Running LM Evals End-to-End
I’ve been working on LLM and AI Agents for a while, but I’d never actually run a proper LM eval from start to finish, so I decided to fix that.
I set up LM Evaluation Harness and ran a few models through it, mainly the Pythia series. Everything logs to Weights & Biases, and I automated batch runs to compare across tasks.
A snapshot from the run:
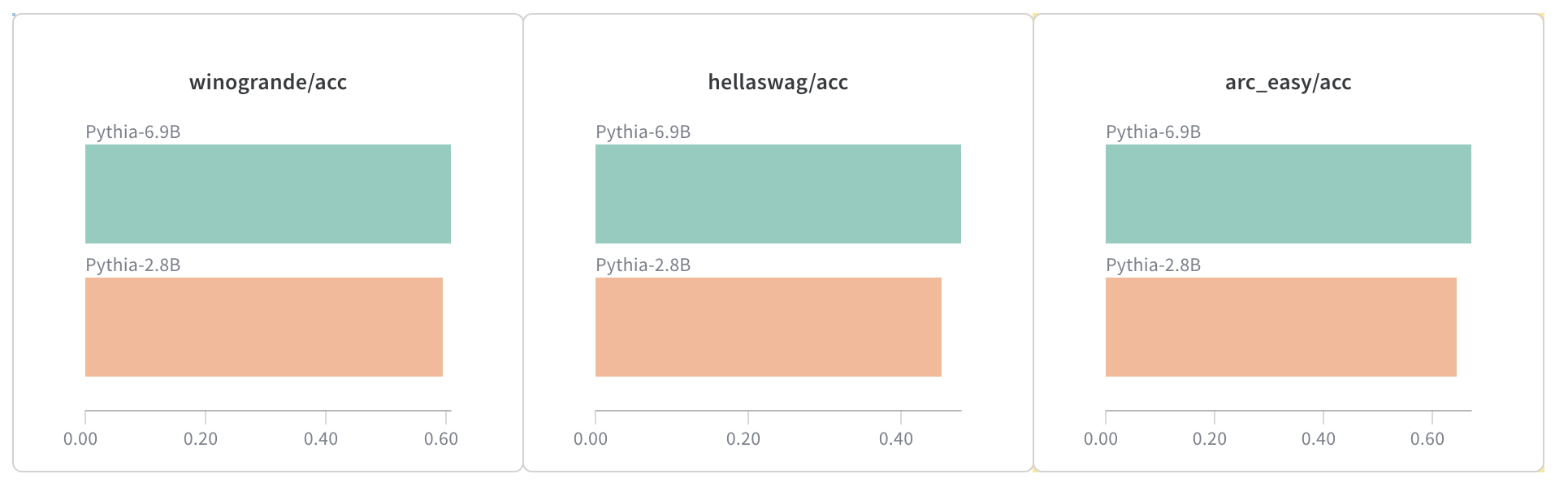
Scaling trends are clear - the larger model consistently outperforms the smaller one across all tasks. The improvements are modest though, with gains of 3-5 percentage points.
That’s it for this round. Just wanted to get proper baselines before diving into custom eval setups. This will be part of a weekly series where I’ll share my findings and experiments with LM evaluations.